BJC -- A Buct Java Compiler
Buct-Java-Compiler
运行环境
1 | Distributor ID: Ubuntu |
项目简介
规则参考来源:
https://github.com/Dayunxi/LL1-Compiler
https://github.com/shellphy/jack-compiler
项目概述
该项目旨在设计和实现一个类似Java语言的编译器。通过这个编译器,用户可以编写使用类和对象、面向对象特性以及类似Java语法的程序,并将其编译成可执行的机器代码或目标代码。编译器将完成从源代码到目标代码的转换过程,包括词法分析、语法分析、语义分析和目标代码生成等阶段。
项目结构
1 | . |
CMakeLists.txt:CMake构建系统的配置文件,用于定义项目的构建规则和依赖关系。Makefile:用于GNU Make构建工具的配置文件,定义了项目的编译规则和依赖关系。Readme.md:项目的说明文档,包含项目的简介、使用方法、贡献指南等信息。rules目录:存放接口相关的文件,以.java为扩展名,用于语法规则。include目录:包含项目的头文件(.h文件),用于声明各个模块的接口和数据结构。inputs目录:存放输入文件的目录,可能包含多个.java文件,如demo1_HelloWorld.java、demo2_Array.java等,用于测试编译器的输入。src目录:包含项目的源代码文件,包括各个模块的实现文件(.cpp文件)和主程序文件(main.cpp)。tests目录:包含项目的测试代码,用于验证编译器的功能和正确性。该目录下可能包含多个测试文件和相关的配置文件(如Makefile)
CMake Workflow
CMake是一个跨平台的构建工具,用于管理和构建项目的代码。它允许开发者使用简单的描述文件来定义项目的构建过程,并生成适用于不同编译器和操作系统的构建脚本。
在GitHub仓库中设置CMake Workflow,利用CMake的跨平台、简化构建过程、自动化构建、可扩展性和社区支持等优势,更高效地管理和构建项目,提高开发效率和代码质量。
CMake and Make
使用CMake和Make来进行编译,旨在简化开发过程。通过使用CMake轻松定义项目的构建规则和依赖关系,并生成适用于不同平台和编译器的构建脚本。Make作为一个常用的构建工具,配合CMake使用,可以根据Makefile中定义的编译规则和依赖关系,自动构建项目。Make的强大功能使得编译过程更加高效和可靠,特别是对于大型项目和需要频繁构建的场景。
本项目cmake结构如下:
1 | cmake_minimum_required(VERSION 3.22) |
使用教程
1、将远程仓库克隆到本地
1 | git clone git@github.com:Sweet196/Compiler.git |
2、使用cmake编译project
1 | cmake . |
3、生成的可执行文件会产生在output文件夹下。使用前需要做以下操作:
1 | cp -r inputs output/ |
4、进入output文件夹执行。提供了三个测试用例,每个使用前都需要将文件名改成Main,否则会触发规定的classname error
1 | cd output |
此外,我们分别提供了模块化测试的功能,存放在了tests文件夹中。进行通过如下命令使用:
1 | cd tests |
需要注意的是,tests文件夹内的测试仅包含了对HelloWorld.java的用例测试,对于其他功能(如语法分析中对各类接口的调用,生成规则及使用),可以自行编写测试。
inputs中提供了3个测试用例,提供的demo1如下:
demo1: HelloWorld
1
2
3
4
5
6class Main {
function void demo1_HelloWorld() {
Output.printString("Hello, world!");
return;
}
}
词法分析
对应文件:Scanner
识别源程序中的单词(token);通过扫描之后在output.txt中写入程序中的所有token及其kind。其中kind表示token的词性或类型。
状态转移图
词法规则使用了正则表达式来定义,可以画出状态转移图(FA)。状态机转移图中的状态定义如下:
| States definition | Meaning |
|---|---|
| START_STATE | 开始状态 |
| ID_STATE | 标识符状态 |
| INT_STATE | 整型数状态 |
| CHAR_STATE | 字符状态 |
| FLOAT_STATE | 浮点数状态 |
| D_FLOAT_STATE | 带小数点的浮点数状态 |
| E_FLOAT_STATE | 科学技术法的浮点数状态 |
| STRING_STATE | 字符串状态 |
| S_STRING_STATE | 含有转移字符的字符串 |
| SYMBOL_STATE | 符号状态 |
| INCOMMENT_STATE | 注释状态 |
| P_INCOMMENT_STATE | 快要结束注释状态 |
| DONE_STATE | 结束状态 |
| ERROR_STATE | 错误状态 |
TokenType
在Scanner::Token结构体中,kind表示标记(Token)的类型。它是Scanner::TokenType枚举类型的一个成员,用于区分不同类型的标记。
Scanner::TokenType枚举类型定义了不同的标记类型,包括:
| Member | Description | KIND |
|---|---|---|
KEY_WORD |
关键字 | 0 |
ID |
标识符 | 1 |
INT |
整型数字 | 2 |
BOOL |
布尔类型 | 3 |
CHAR |
字符 | 4 |
STRING |
字符串 | 5 |
SYMBOL |
合法的符号 | 6 |
NONE |
无类型 | 7 |
ERROR |
错误 | 8 |
ENDOFFILE |
文件结束 | 9 |
保留字与关键字
支持以下符号:
| Category | Classification | Content | |
|---|---|---|---|
| Keywords | Class related | class, constructor, function, method, field, static | |
| Function related | int, char, boolean, void, true, false, this | ||
| Control flow related | if, else, while, return | ||
| Operators | Delimiters | {, }, (, ), [, ], ., ,, ; | |
| Arithmetic operators | +, -, *, / | ||
| Logical operators | &,\ | ,~ | |
| Comparison operators | <, >, =, ==, != |
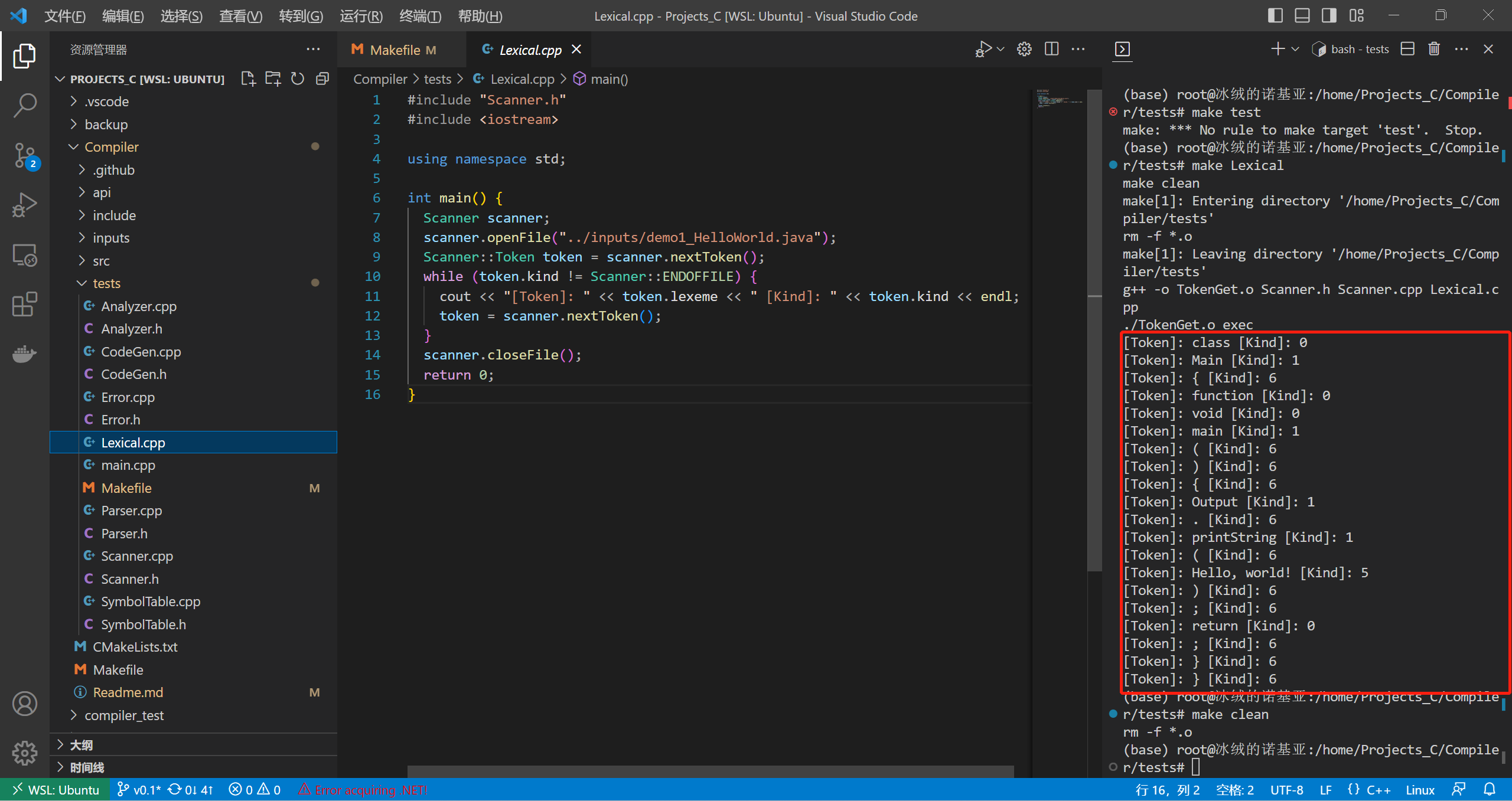
编写主函数进行测试,可得到词法分析结果:
1 |
|
语法分析
对应文件:Parser.cpp
使用递归下降的方法实现。递归下降(Recursive Descent)是一种常用的自顶向下的语法分析方法,用于将输入的源代码逐个标记(Token)地解析为语法树(Parse Tree)。在递归下降方法中,语法规则的每个非终结符对应一个递归函数,这些函数相互调用以实现语法分析。
语法分析的任务
语法分析具有两个任务
- 判断源程序是否符合语法规则
- 生成抽象语法树
产生式
编译器使用了上下文无关文法(BNF)进行定义,下面是对上述文法中每个产生式(Production)的解释:
program -> classlist: 程序由类列表组成。classlist -> classlist class | class: 类列表由一个或多个类组成。class -> class ID { classVarDecList subroutineDecList }: 类由类名、类变量声明列表和子例程声明列表组成。classVarDecList -> classVarDecList classVarDec | ε: 类变量声明列表由一个或多个类变量声明组成,或为空。classVarDec -> static type varNameList ; | field type varNameList ;: 类变量声明包括静态变量声明和字段声明。varNameList -> varNameList , ID | ID: 变量名列表由一个或多个变量名组成,用逗号分隔。type -> int | float | char | boolean | void | ID: 类型可以是int、float、char、boolean、void或标识符。subroutineDecList -> subroutineDecList subroutineDec | ε: 子例程声明列表由一个或多个子例程声明组成,或为空。subroutineDec -> constructor type ID ( params ) subroutineBody | function type ID ( params ) subroutineBody | method type ID (params ) subroutineBody: 子例程声明包括构造函数声明、函数声明和方法声明。params -> paramList | ε: 参数由参数列表组成,或为空。paramList -> paramList , param | param: 参数列表由一个或多个参数组成,用逗号分隔。param -> type ID: 参数由类型和标识符组成。subroutineBody -> { varDecList statements }: 子例程体由变量声明列表和语句组成。varDecList -> varDecList varDec | ε: 变量声明列表由一个或多个变量声明组成,或为空。varDec -> type varNameList ;: 变量声明由类型和变量名列表组成。statements -> statements statement | ε: 语句由一个或多个语句组成,或为空。statement -> assign_statement | if_statement | while_statement | return_statement | call_statement ;: 语句可以是赋值语句、条件语句、循环语句、返回语句或调用语句。assign_statement -> leftValue = expression ;: 赋值语句由左值、等号和表达式组成。leftValue -> ID | ID [ expression ]: 左值可以是标识符或标识符后跟方括号的表达式。if_statement -> if ( expression ) statement | if ( expression ) statement else statement: 条件语句可以是带有或不带有else子句的if语句。while_statement -> while ( expression ) { statement }: 循环语句由循环条件和循环体组成。return_statement -> return ; | return expression ;: 返回语句可以是空返回或带有返回表达式。call_statement -> ID ( expressions ) | ID . ID ( expressions ): 调用语句可以是函数调用或方法调用。expressions -> expression_list | ε: 表达式由表达式列表组成,或为空。expression_list -> expression_list , expression | expression: 表达式列表由一个或多个表达式组成,用逗号分隔。expression -> expression & boolExpression | expression | boolExpression: 表达式可以是逻辑与操作、逻辑或操作或布尔表达式。boolExpression -> additive_expression relational_operator additive_expression | additive_expression: 布尔表达式由加法表达式和关系运算符组成,或仅由加法表达式组成。relational_operator -> <= | >= | == | < | > | !=: 关系运算符可以是小于等于、大于等于、等于、小于、大于或不等于。additive_expression -> additive_expression + term | additive_expression – term | term: 加法表达式由加法、减法或项组成。term -> term * factor | term / factor | factor: 项由乘法、除法或因子组成。factor -> - positive_factor | positive_factor: 因子可以是负数因子或正数因子。positive_factor -> ~ not_factor | not_factor: 正数因子可以是按位取反的因子或非按位取反的因子。not_factor -> INT_CONST | CHAR_CONST | STRING_CONST | keywordConstant | ID | ID [ expression ] | call_expression | ( expression ): 非因子可以是整数常量、字符常量、字符串常量、关键字常量、标识符、标识符后跟方括号的表达式、调用表达式或括号中的表达式。keywordConstant -> true | false | null | this: 关键字常量可以是true、false、null或this。call_expression -> ID ( expression ) | ID . ID ( expression ): 调用表达式可以是函数调用或方法调用。
这些产生式描述了程序中各个语法成分之间的结构关系,用于构建语法分析器以解析程序代码。
以下是不同语法树节点对应的输出:
| \Case** | \Output** | \Node Name** |
|---|---|---|
| CLASS_K | class | 类节点 |
| CLASS_VAR_DEC_K | class_var_dec | 类变量声明节点 |
| SUBROUTINE_DEC_K | subroutine_dec | 函数声明节点 |
| BASIC_TYPE_K | basic_type |
基本类型节点 |
| CLASS_TYPE_K | class_type |
类类型节点 |
| PARAM_K | param | 参数节点 |
| VAR_DEC_K | var_dec | 变量声明节点 |
| ARRAY_K | array | 数组节点 |
| VAR_K | var | 变量节点 |
| IF_STATEMENT_K | if_statement | 条件语句节点 |
| WHILE_STATEMENT_K | while_statement | 循环语句节点 |
| RETURN_STATEMENT_K | return_statement | 返回语句节点 |
| CALL_STATEMENT_K | call_statement | 调用语句节点 |
| BOOL_EXPRESSION_K | bool_expression |
布尔表达式节点 |
| COMPARE_K | compare |
比较节点 |
| OPERATION_K | operation |
操作节点 |
| BOOL_K | bool | 布尔节点 |
| ASSIGN_K | assign | 赋值节点 |
| SUBROUTINE_BODY_K | subroutine_body | 函数体节点 |
对于输入的一个示例的输入文件Main.java,可获得如下抽象语法树.由上至下分别代表类节点,函数声明节点,基本类型节点(void),函数体节点,调用语句节点,返回语句节点。
1 | class |
语义分析
分析过程:通过对语法分析的结果(语法树)进行分析,判断语义错误,若有错输出错误内容。
成员函数:
class Analyzer {
private:
Parser::TreeNode *tree;
SymbolTable *symbolTable;
string currentClassName; // 遍历树的时候, 保存当前类的名称
string currentFunctionName; // 遍历树的时候, 保存当前函数的名称
void buildClassesTable(Parser::TreeNode *t);
void checkStatements(Parser::TreeNode *t);
void checkStatement(Parser::TreeNode *t);
void checkExpression(Parser::TreeNode *t);
void checkArguments(Parser::TreeNode *t, vector const& parameter,
string const& functionName);
void checkMain();
public:
Analyzer(Parser::TreeNode *t);
void check();
};
### 分析过程
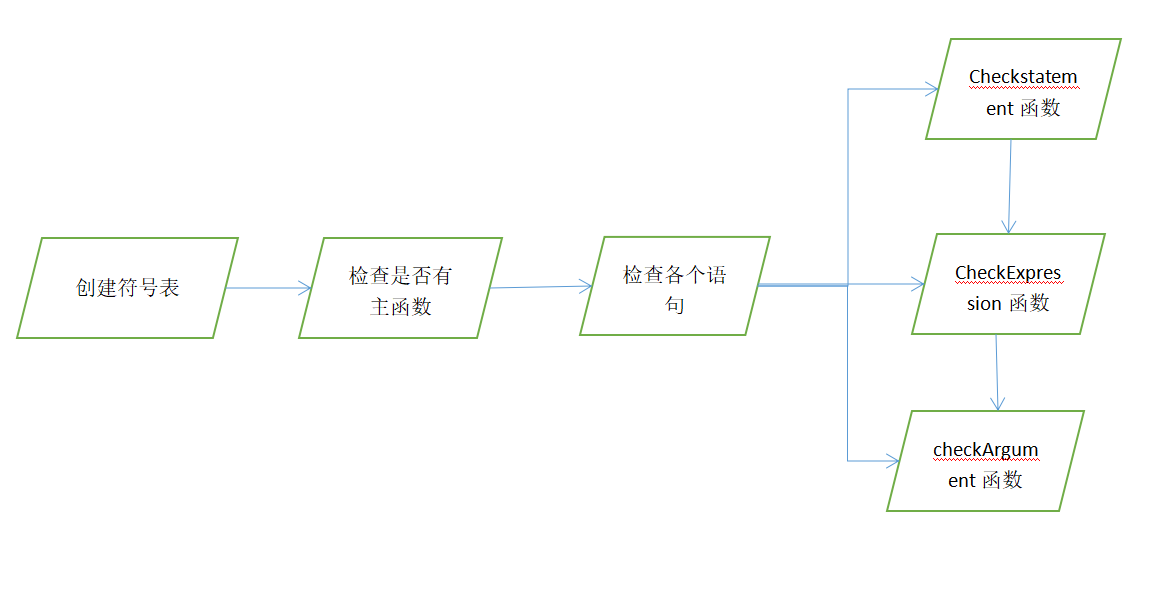
首先通过函数buildClassesTable递归构建符号表中的类定义部分,将类的信息插入到符号表中,然后由函数checkMain:检查程序中是否存在名为Main的类,并验证其中是否存在名为main的静态函数,满足main函数的特定要求,最后函数checkStatements:递归检查语法树中的语句列表,将子过程的信息插入符号表,并调用checkStatement函数对每个语句进行语义检查,
checkStatement:检查赋值语句、条件语句、循环语句、返回语句和函数调用语句的语义正确性(其中调用函数函数checkExpression和函数checkArguments)。
### 函数详细描述
构造函数Analyzer::Analyzer(Parser::TreeNode *t):接收一个指向语法树节点的指针,并初始化symbolTable和tree成员变量。
函数checkExpression:该函数用于检查语法树中的表达式部分的语义正确性。
函数首先检查传入的语法树节点是否为nullptr,如果不是,则对节点的子节点进行递归调用checkExpression函数。
然后,根据节点的类型(nodeKind)执行相应的操作:
如果节点类型为VAR_K,表示该节点为变量,函数会在符号表中查找变量的信息。首先在当前子程序的符号表中查找,如果找不到,则在当前类的符号表中查找。如果仍然找不到,则调用error5函数报告错误。
如果节点类型为ARRAY_K,表示该节点为数组变量,函数会在符号表中查找数组变量的信息,与上述步骤相同。如果找到了变量信息,还会检查变量的类型是否为"Array",如果不是,则调用error6函数报告错误。
如果节点类型为CALL_EXPRESSION_K或CALL_STATEMENT_K,表示该节点为函数调用表达式或语句。函数首先检查调用的函数是否在当前类中声明,如果未找到,则调用error7函数报告错误。然后,检查当前子程序和被调用的函数是否都是方法(即类中的成员函数)。如果是,则调用error8函数报告错误。接下来,函数会在符号表中查找函数的信息,并使用checkArguments函数检查函数调用的参数是否匹配。最后,根据被调用函数的类型,将节点的nodeKind设置为相应的值(METHOD_CALL_K、FUNCTION_CALL_K或CONSTRUCTOR_CALL_K)。
如果节点类型不匹配上述情况,函数将执行默认操作,即不进行任何处理。
以上是checkExpression函数的主要功能。它通过递归遍历语法树,检查表达式中的变量、数组、函数调用等部分的语义正确性,并在发现错误时调用相应的错误处理函数报告错误。
函数checkStatement:该函数用于检查语法树中的语句部分的语义正确性。
函数根据语法树节点的类型(nodeKind)执行相应的操作:
如果节点类型为CLASS_K,表示该节点为类声明,函数会将当前类的名称设置为节点的第一个子节点的词素(token.lexeme)。
如果节点类型为ASSIGN_K,表示该节点为赋值语句,函数会分别检查赋值语句的左侧表达式和右侧表达式的语义正确性,通过调用checkExpression函数进行检查。
如果节点类型为IF_STATEMENT_K或WHILE_STATEMENT_K,表示该节点为条件语句(if语句或while循环语句),函数会检查条件表达式的语义正确性,通过调用checkExpression函数进行检查。
如果节点类型为RETURN_STATEMENT_K,表示该节点为返回语句,函数会检查返回表达式的语义正确性,通过调用checkExpression函数进行检查。同时,函数还会在特定情况下进行额外的错误检查,包括检查返回值是否与当前子程序的返回类型匹配、检查构造函数是否在返回语句中使用了"this"关键字等。
如果节点类型为CALL_STATEMENT_K,表示该节点为函数调用语句,函数会直接调用checkExpression函数对该节点进行检查。
如果节点类型不匹配上述情况,函数将执行默认操作,即不进行任何处理。
以上是checkStatement函数的主要功能。它根据语法树节点的类型执行相应的操作,对语句中的表达式、条件语句、返回语句和函数调用语句等部分进行语义正确性检查,并在发现错误时调用相应的错误处理函数报告错误。
函数checkArguments:该函数用于检查函数调用的参数是否与函数定义的参数匹配。
函数首先定义一个变量argumentSize,用于记录实际参数的个数,并初始化为0。
然后,函数使用循环遍历函数调用语句节点的子节点,即实际参数的表达式节点。对于每个参数节点,函数调用checkExpression函数进行语义检查,并将argumentSize增加1。
接下来,函数会进行参数个数的匹配检查。如果实际参数的个数小于形式参数的个数,说明参数个数不足,调用error14函数报告错误。
如果实际参数的个数大于形式参数的个数,说明参数个数过多,调用error15函数报告错误。
如果实际参数的个数与形式参数的个数相等,则参数匹配正确,不进行任何处理。
以上是checkArguments函数的主要功能。它通过循环遍历实际参数节点,进行语义检查,并比较实际参数个数与形式参数个数的匹配情况,根据不同情况调用相应的错误处理函数报告错误。
函数check:该函数用于进行语义分析的入口。
函数首先调用buildClassesTable函数,该函数根据语法树构建类符号表。它遍历语法树,收集类的信息并添加到符号表中。
接下来,函数调用checkMain函数,该函数用于检查是否存在Main类和main函数,以及其正确性。
然后,函数调用checkStatements函数,该函数对语法树中的所有语句进行语义分析。它遍历语法树,针对不同类型的语句调用相应的检查函数进行语义分析。
以上是check函数的主要功能。它在语义分析过程中完成了类符号表的构建、Main类和main函数的检查,以及对语句部分的语义分析。
函数checkMain:该函数用于检查是否存在Main类和main函数,并对其进行正确性验证。
函数首先使用symbolTable->classIndexFind("Main")检查符号表中是否存在名为Main的类。如果不存在,调用error16函数报告错误。
接着,函数使用symbolTable->classesTableFind("Main", "main")查找Main类中是否存在名为main的函数。如果不存在,调用error17函数报告错误。
然后,函数检查找到的main函数的类型(kind)是否为函数类型(FUNCTION)。如果不是,调用error18函数报告错误。
接下来,函数检查找到的main函数的返回类型(type)是否为void。如果不是,调用error19函数报告错误。
最后,函数检查找到的main函数的参数列表(args)是否为空。如果不为空,调用error20函数报告错误。
以上是checkMain函数的主要功能。它用于检查Main类和main函数是否存在,并对其进行正确性验证,包括检查返回类型、参数列表等。在发现错误时,调用相应的错误处理函数报告错误。
函数buildClassesTable:该函数用于构建符号表中的类定义部分。
以下是函数的主要步骤:
声明一个静态变量depth,并将其初始化为0。该变量用于跟踪递归的深度。
如果depth大于2,则函数直接返回,避免无限递归。
进入一个循环,处理当前节点t及其后续节点。
在循环中,将当前节点t插入到符号表的类表(classesTableInsert)中,以记录类的定义信息。
对于当前节点t的每个子节点(最多5个),递归调用buildClassesTable函数,并将depth加1。这样可以逐层遍历语法树的子树,构建类定义的符号表。
递归调用结束后,将depth减1。
将当前节点t移动到下一个兄弟节点,继续处理下一个节点。
通过以上步骤,buildClassesTable函数可以遍历语法树中的类定义部分,并将类的信息插入到符号表中,以备后续的语义分析使用。函数中的深度限制(depth > 2)可以控制递归的层级,以避免无限递归或过度深入的问题。
函数checkStatements:该函数用于对语法树中的语句进行语义分析。
函数通过一个循环遍历语法树中的语句节点,每次迭代处理一个语句节点。
在循环的每个迭代中,首先调用symbolTable->subroutineTableInsert(t)将当前语句节点t插入子程序符号表中。这是为了记录当前语句所在的子程序(函数或方法)的信息,以便后续的语义分析。
接下来,函数调用checkStatement(t)对当前语句节点进行语义分析。根据语句节点的类型,调用相应的检查函数对语句进行处理。
然后,函数通过一个循环遍历当前语句节点的子节点,即该语句的子语句节点。对于每个子语句节点,递归调用checkStatements函数进行语义分析。
最后,函数更新当前语句节点为下一个兄弟节点,即进入下一个迭代。这样可以确保循环能够遍历所有的语句节点。
以上是checkStatements函数的主要功能。它通过循环遍历语法树中的语句节点,将每个语句节点插入子程序符号表,对每个语句节点进行语义分析,并递归处理每个语句节点的子语句节点。这样可以对整个语法树中的语句进行全面的语义分析。
这些函数共同完成了对语法树的语义分析,包括构建符号表、检查表达式、检查语句、检查函数调用等,以确保程序的语义正确性。
### 错误列表
对应文件`Error.cpp`
| 函数名 | 错误类型 |错误信息 |
| :---------------- | ---------------------- | --------------------------------------------------------------------------------------------------------|
| syntaxError | 语法错误 |在当前解析器文件(currentParserFilename)的第 token.row 行,期望一个 expected,但实际得到一个 token.lexeme。 |
| error1 | 类名和文件名不一致。 |在文件 currentParserFilename.java 中,类名应该和文件名相同。 |
| error2 | 变量重定义 |在当前类 currentClass 的第 row 行,变量类型为 type,变量名为 name,已经被重定义。 |
| error3 | 函数重定义 |在当前类 currentClass 的第 row 行,函数返回类型为 type,函数名为 name,已经被重定义。 |
| error4 | 类型未定义 |在当前类 currentClassName 的第 row 行,类型 type 未定义 |
| error5 | 变量未定义 |在当前类 currentClassName 的第 row 行,变量 varName 在当前作用域中未声明 |
| error6 | 类型不是数组类型 |在当前类 currentClassName 的第 row 行,类型 type 不是数组类型 |
| error7 | 调用类中不存在的成员函数|在当前类 currentClassName 的第 row 行,类 callerName 中不存在函数 functionName() |
| error8 | 调用函数用了错误的调用方式|在当前类 currentClassName 的第 row 行,子程序 functionName 被当成了一个方法,但实际上它是在函数内被调用的 |
| error9 | 在类中调用了不存在的函数|在当前类 currentClassName 的第 row 行,类 callerName 中不存在函数 functionName |
| error10 |调用不是当前类的成员函数|在当前类 currentClassName 的第 row 行,函数 functionName 不是类 callerName 的成员函数 |
| error11 | 函数返回值类型错误 |在当前类 currentClassName 的第 row 行,函数返回了空值,但实际上返回类型应该是 type |
| error12 | 函数返回值类型错误 |在当前类 currentClassName 的第 row 行,函数返回了值,但实际上返回类型应该是 void |
| error13 | 构造函数返回值类型错误 |在当前类 currentClassName 的第 row 行,构造函数返回类型必须是类类型 |
| error14 | 函数参数数量不足 |在当前类 currentClassName 的第 row 行,函数 functionName() 的参数数量过少 |
| error15 | 函数参数数量过多 |在当前类 currentClassName 的第 row 行,函数 functionName() 的参数数量过多 |
| error16 |主类不存在 |主类不存在 |
| error17 | 主类中没有 main 函数 |在主类中,main 函数不存在 |
| error18 | main 函数的类型不正确 |在主类中,main 函数的类型必须是函数类型 |
| error19 | main 函数返回类型不正确 |在主类中,main 函数的返回类型必须是 void |
| error20 | main 函数参数数量不正确 |在主类中,main 函数的参数数量必须为 null |
每出现一个错误将会对错误数量进行累计计数,同时继续扫描剩余内容,直到指针到达文件末尾。error将全部返回并输出。
例:对于一个不包含`main()`的程序,如下所示,会返回以下错误:
1 | class Main{ |
translate():根据节点的类型选择相应的操作。在每个 case 中,根据节点类型执行相应的操作,例如处理赋值语句、方法调用、循环语句、条件语句等。这些操作会调用其他函数来生成相应的汇编代码。 writeExpression():通过递归遍历表达式树来生成相应的汇编代码。根据表达式节点的类型,执行相应的操作。例如,对于算术运算节点,调用 writeArithmetic 函数生成相应的算术指令;对于变量节点,调用 writePush 函数将变量的值压入堆栈。 writePush()、writePop():根据指定的段和索引生成相应的汇编代码,将值从指定的段读取或写入堆栈。 writeArithmetic():根据指定的算术操作生成相应的汇编代码。
总结与展望
通过本次编译器项目的开发,我们成功地设计和实现了一个类似Java语言的编译器,并完成了基本的输入输出功能。在项目的过程中,我们经历了词法分析、语法分析、语义分析和目标代码生成等多个阶段,每个阶段都提供了独特的挑战和学习机会。
总结
- 成果与挑战:通过团队的协作努力,我们成功地实现了基本的编译器功能,包括词法分析、语法分析、语义分析和目标代码生成。我们学习并掌握了编译原理的核心概念和算法,并将其应用于实际的编译器开发中。同时,我们也面对了各种挑战,如语法规则的设计、错误处理、符号表管理等,这些挑战提高了我们的编程技能和问题解决能力。
- 项目管理与合作:通过采用CMake和Make进行项目的构建,我们实现了项目的模块化和自动化,简化了开发过程。在团队合作方面,我们通过有效的沟通和任务分工,实现了高效的协作开发,确保了项目的进度和质量。
- 学习与成长:本次项目为我们提供了一个深入理解编译原理和语言设计的机会。通过手动实现编译器的各个阶段,我们加深了对编译器工作原理的理解,并提升了编程技能和代码质量控制的能力。
展望
尽管我们在时间有限的情况下完成了基本的输入输出功能,但是仍有许多有趣的方向可以进一步拓展和改进。以下是对未来发展的展望:
- 扩展语言功能:作为一个自创的类似Java语言,我们可以进一步扩展其功能和语法规则,使其更接近真实的Java语言。例如,支持更多的数据类型、控制结构、异常处理等特性,使我们的语言更加强大和实用。
- 实现高级特性:我们可以探索实现一些高级的编程特性,如泛型、反射、注解等,以增加语言的灵活性和可扩展性。
- 优化和性能提升:我们可以对编译器进行优化,提高生成的目标代码的质量和执行效率。可以使用更高级的优化技术,如常量折叠、死代码消除、循环展开等,以提高生成的目标代码的性能。
- 支持更多工具和库:为了增强我们的编译器的实用性,可以考虑与其他工具和库进行集成,如调试器、测试框架、标准库等。
总的来说,我们已经取得了令人骄傲的成果,但编译器开发是一个庞大而复杂的领域,仍有许多发展的空间。通过继续学习和探索,我们可以不断提升自己的编译器开发技能,进一步完善我们的编译器,并为其他开发者提供更强大和易用的工具。