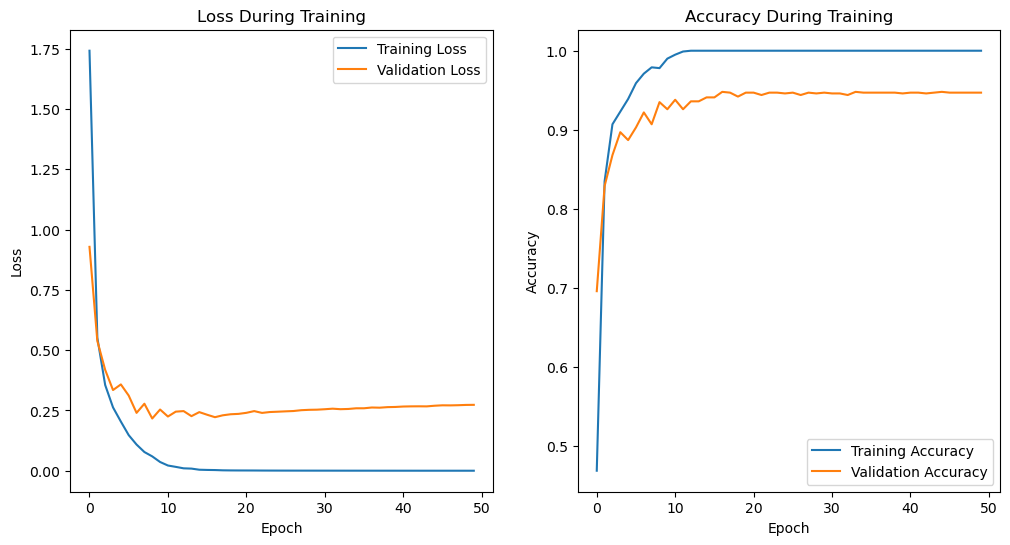
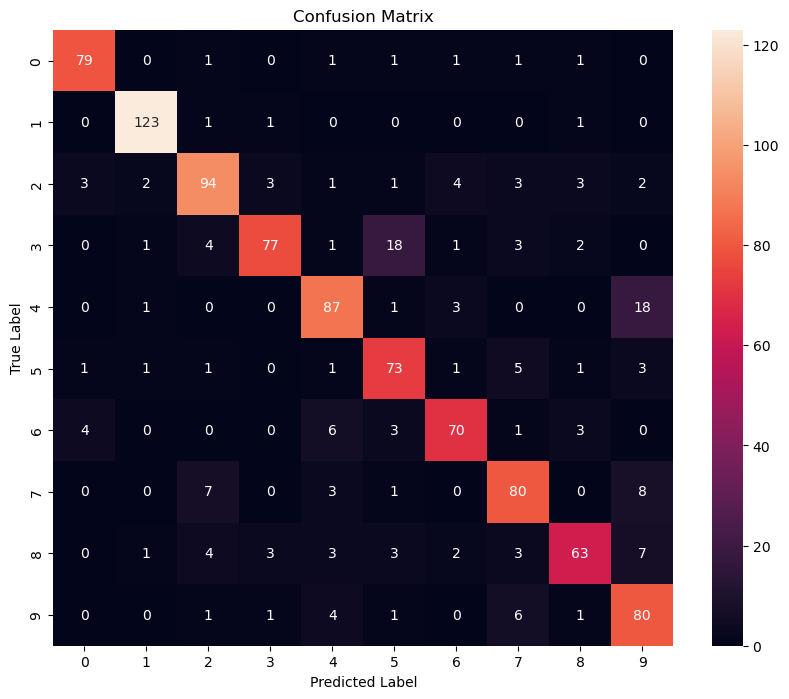
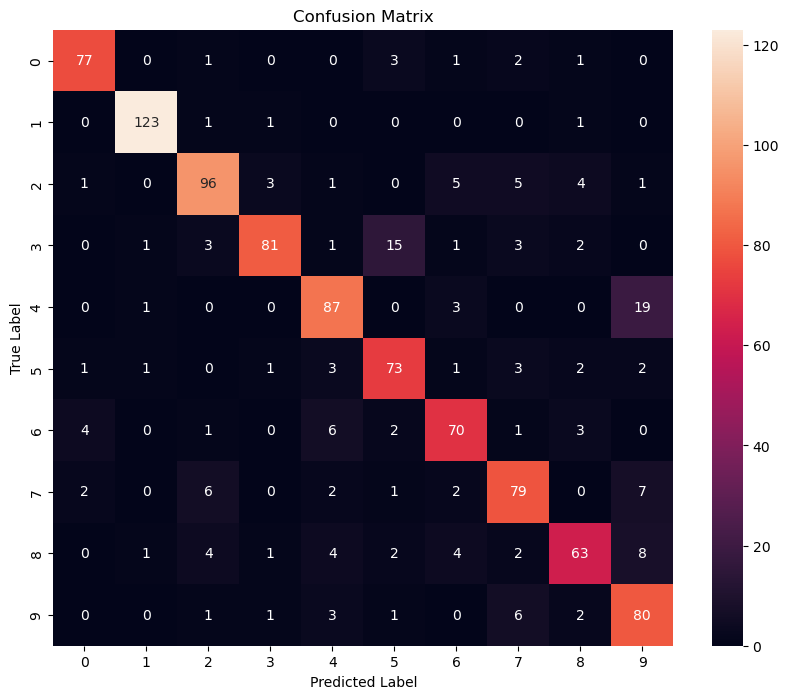
This Chapter contains normal ML Algorithms in CIS Lectures. The mnist dataset was selected for demonstration. It is worth noting that only 1000 samples were used for training and testing here, in order to accelerate the demonstration process. If better performance is to be achieved, all training and testing data should be used.
I will appreciate if you give my repository a star all follow my channel. Plzzzzzzzz!!!!
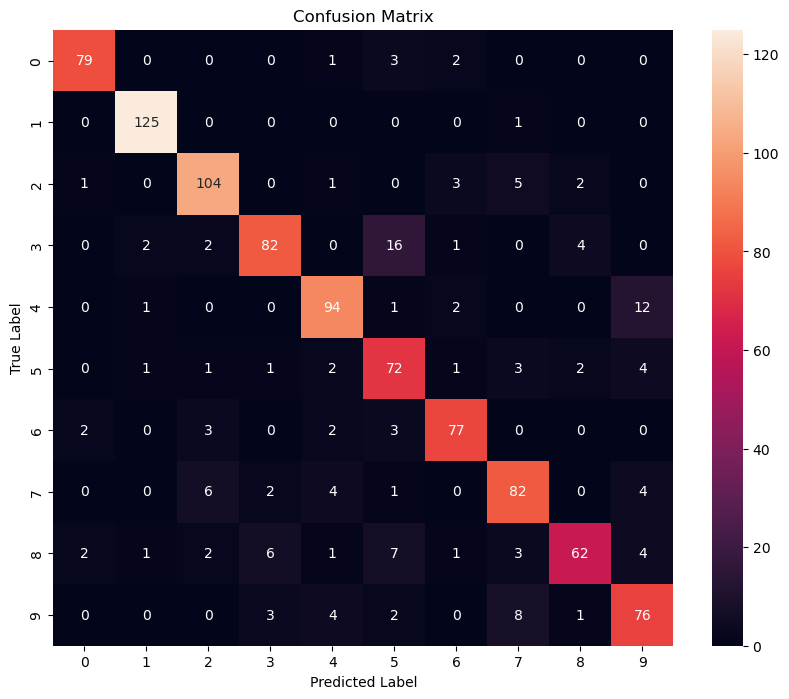
SVM: Support Vector Machine
Support Vector Machine (SVM) is a popular machine learning algorithm used for classification and regression analysis. The basic idea behind SVM is to find a hyperplane in a high-dimensional space that separates the different classes of data points as best as possible. In other words, SVM tries to find the boundary between two classes of data by maximizing the margin between them. This margin is the distance between the closest data points of each class to the separator or hyperplane.
SVM can also handle non-linearly separable datasets through a technique called kernel trick, which maps the input data into a higher-dimensional space where it becomes linearly separable. Some popular kernel functions include linear, polynomial, radial basis function (RBF), and sigmoid.
SVM has been widely used in various fields such as image recognition, text classification, bioinformatics, and finance due to its effectiveness in handling complex datasets and relatively good performance in comparison to other algorithms.
from tensorflow.keras.datasets import mnist from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt from sklearn.svm import SVC import seaborn as sns
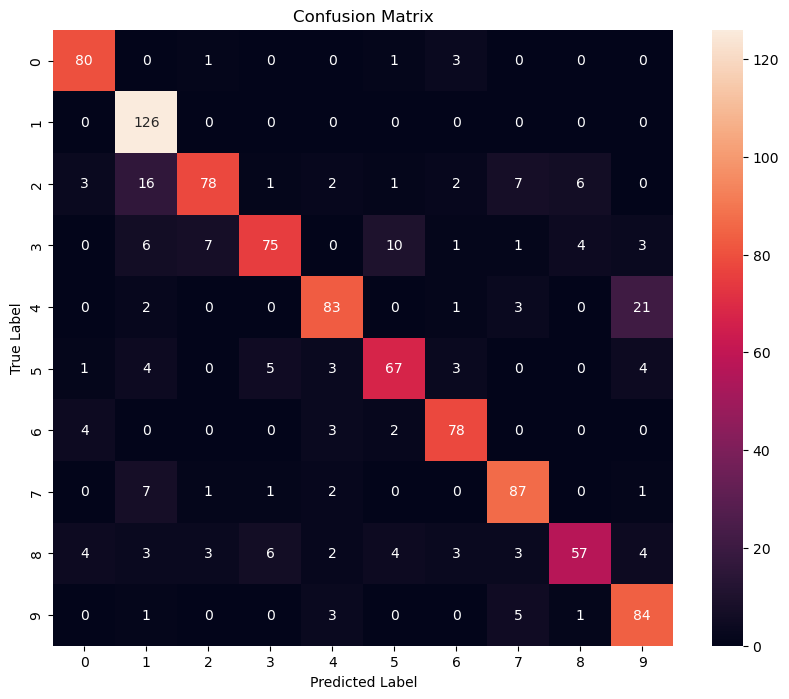
KNN (K-Nearest Neighbor) is one of the simplest machine learning algorithms, which can be used for classification and regression. It is a supervised learning algorithm. Its idea is that if most of the K most similar (i.e. closest) samples in the feature space belong to a certain category, then the sample also belongs to that category. That is to say, this method only determines the category of the sample to be divided based on the category of the nearest one or several samples in the classification decision.
from tensorflow.keras.datasets import mnist from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier import seaborn as sns
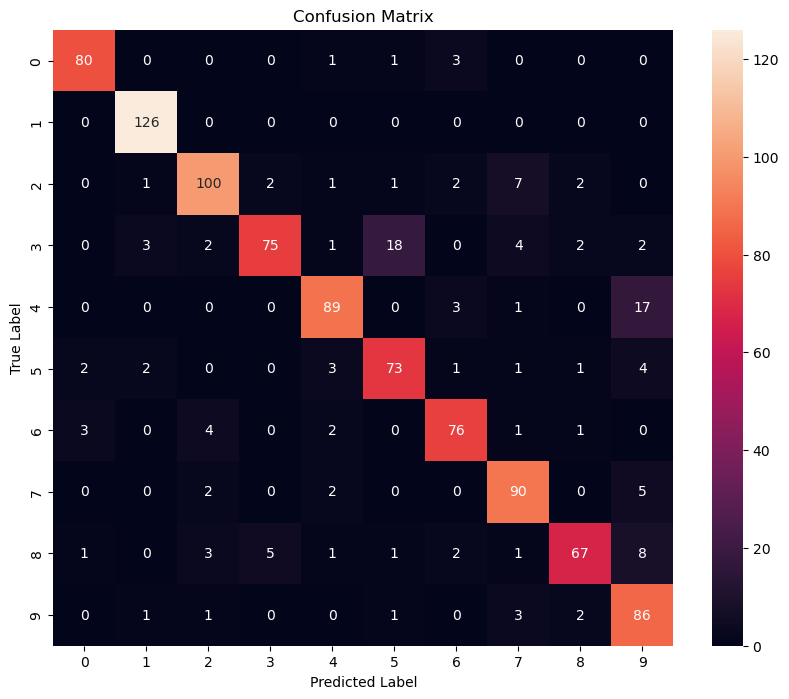
Tree models where the target variable can take a discrete set of values are called classificationtrees; in these tree structures, leaves represent class labels and branches represent conjunctions of features that lead to those class labels. Decision trees where the target variable can take continuous values (typically real numbers) are called regressiontrees. More generally, the concept of regression tree can be extended to any kind of object equipped with pairwise dissimilarities such as categorical sequences.[1]
Decision trees are among the most popular machine learning algorithms given their intelligibility and simplicity.[2]
In decision analysis, a decision tree can be used to visually and explicitly represent decisions and decision making. In data mining, a decision tree describes data (but the resulting classification tree can be an input for decision making).
from tensorflow.keras.datasets import mnist from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier import seaborn as sns
from tensorflow.keras.datasets import mnist from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt from sklearn.ensemble import RandomForestClassifier import seaborn as sns
Classic gradient lifting tree: XGBoost and LightGBM. Some differences between them:
Computational efficiency: LightGBM uses a histogram like technique when constructing decision trees, which can quickly find the optimal splitting point. Therefore, when training large datasets, LightGBM is usually faster than XGBoost.
Memory usage: LightGBM uses column based storage to reduce memory usage. This makes LightGBM more suitable for processing large high-dimensional data.
Regularization: XGBoost supports regularization technology to avoid overfitting, such as L1 and L2 regularization, feature importance ranking, etc. LightGBM only supports L2 regularization.
Distributed computing: XGBoost has built-in distributed computing capabilities, which can train models in parallel on multiple nodes. LightGBM currently does not support distributed computing.
Data sampling method: XGBoost adopts an instance based sampling method, which randomly selects a subset as the training set for each decision tree. LightGBM adopts a feature based sampling method, which samples features to select subsets.
Overall, XGBoost and LightGBM perform well in practice, with the main difference being their design philosophy and implementation details. When choosing an algorithm, it should be based on the characteristics of the specific problem. If you need to process large-scale high-dimensional data, you can consider using LightGBM; If you need regularization or distributed computing, you can consider using XGBoost.
import xgboost as xgb from sklearn.metrics import accuracy_score, confusion_matrix import matplotlib.pyplot as plt import seaborn as sns from tensorflow.keras.datasets import mnist import numpy as np
# Reshape the data for training and testing X_train = X_train.reshape((60000, 28*28))[:1000] X_test = X_test.reshape((10000, 28*28))[:1000] y_train = y_train.astype(int)[:1000] y_test = y_test.astype(int)[:1000]
# Create DMatrix objects from the data dtrain = xgb.DMatrix(X_train, label=y_train) dtest = xgb.DMatrix(X_test, label=y_test)
# Define the hyperparameters for the XGBoost model param = { 'max_depth': 3, 'eta': 0.1, 'objective': 'multi:softmax', 'num_class': 10 }
# Train the XGBoost model num_rounds = 50 bst = xgb.train(param, dtrain, num_rounds)
# Predict the labels for the test set preds = bst.predict(dtest)
# Calculate the accuracy of the classifier acc = accuracy_score(y_test, preds) print("Accuracy: {:.2f}%".format(acc * 100))
import lightgbm as lgb from sklearn.metrics import accuracy_score, confusion_matrix import matplotlib.pyplot as plt import seaborn as sns from tensorflow.keras.datasets import mnist import numpy as np
# Reshape the data for training and testing X_train = X_train.reshape((60000, 28*28))[:1000] X_test = X_test.reshape((10000, 28*28))[:1000] y_train = y_train.astype(int)[:1000] y_test = y_test.astype(int)[:1000]
# Create Dataset objects from the data train_data = lgb.Dataset(X_train, label=y_train) test_data = lgb.Dataset(X_test, label=y_test)
# Define the hyperparameters for the LightGBM model param = { 'max_depth': 3, 'learning_rate': 0.1, 'objective': 'multiclass', 'num_class': 10 }
# Train the LightGBM model num_rounds = 50 bst = lgb.train(param, train_data, num_rounds)
# Predict the labels for the test set preds = bst.predict(X_test) preds = np.argmax(preds, axis=1)
# Calculate the accuracy of the classifier acc = accuracy_score(y_test, preds) print("Accuracy: {:.2f}%".format(acc * 100))