实验一:编写Pthreads程序实现直方图统计 编写一个Pthreads程序实现直方图统计,选择使用忙等待、互斥量和信号量来保证临界区的互斥,并分析方法的优点和缺点。
问题描述: 一个程序生成大量的浮点数并存储在数组里,为了对数据分布有一个直观感受,绘制一个数据直方图。
输入输出 输入:
数据的个数:data_count
一个大小为data_count的浮点数组:data
包含最小值的桶中的最小值:min_meas
包含最大值的桶中的最大值:max_meas
桶的个数:bin_count
输入样例:
1 2 3 20 1 .3 2 .9 0 .4 0 .3 1 .3 4 .4 1 .7 0 .4 3 .2 0 .3 4 .9 2 .4 3 .1 4 .4 3 .9 0 .4 4 .2 4 .5 5 .9 0 .9 5
输出:
bin_maxes:一个大小为bin_count的浮点数组
bin_counts:一个大小为bin_count的整数数组
1 2 3 4 5 6 7 bin_maxes :4 .2 4 .4 4 .4 4 .5 4 .9 5 .9 bin_counts :[0.3,1.3):6 [1.3,2.3):3 [2.3,3.3):4 [3.3,4.3):2 [4.3,5.3):4
其他说明:
桶的宽度bin_width=(max_meas-min_meas)/bin_count
bin_maxes数据初始化
for(b=0;b<bin_count;b++)
bin_maxes[b]=min_meas+bin_width*(b+1)
落在桶b中的数据bin_maxes[b-1]<=measurement<bin_maxes[b]
b=0: min_meas<=measurement<bin_maxes[0]
计数:for(i=0;i<data_count;i++){
bin=Find_bin(data[i],bin_maxes,bin_count,min_meas);
}
问题解决 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 #include <pthread.h> #include <bits/stdc++.h> using namespace std;long data_count;long bin_width;vector<double >datas; double min_meas,max_meas;long bin_count;vector<double >bin_maxes; vector<long >bin_counts; pthread_mutex_t mutexx;void * func (void * rank) long Find_bin (double data,vector<double >bin_maxes,long bin_count,double min_meas) int main () freopen ("testin.txt" ,"r" ,stdin); cout<<"Enter the number of data:" ; cin>>data_count; datas.resize (data_count); cout<<"Enter elements of data:" ; for (long i=0 ;i<data_count;i++){ cin>>datas[i]; } cout<<"Enter the number of bin:" ; cin>>bin_count; bin_maxes.resize (bin_count); bin_counts.resize (bin_count,0 ); max_meas=*max_element (datas.begin (),datas.end ()); min_meas=*min_element (datas.begin (),datas.end ()); bin_width=(max_meas-min_meas)/bin_count; for (long b=0 ;b<bin_count;b++){ bin_maxes[b]=min_meas+bin_width*(b+1 ); } cout<<"bin_maxes:" ; for (auto it=bin_maxes.begin ();it!=bin_maxes.end ();it++){ cout<<*it<<" " ; }cout<<endl; pthread_t * thread=(pthread_t *)malloc (data_count*sizeof (pthread_t )); for (long i=0 ;i<data_count;i++){ pthread_create (&thread[i],NULL ,func,(void *)i); } for (long i=0 ;i<bin_count;i++){ printf ("[%.1lf,%.1lf):%ld\n" ,bin_maxes[i]-bin_width,bin_maxes[i],bin_counts[i]); } return 0 ; } void * func (void * rank) long i=(long )rank; pthread_mutex_lock (&mutexx); long bin=Find_bin (datas[i],bin_maxes,bin_count,min_meas); pthread_mutex_unlock (&mutexx); } long Find_bin (double data,vector<double >bin_maxes,long bin_count,double min_meas) if (data>=min_meas and data<bin_maxes[0 ]){ bin_counts[0 ]++; } else { for (long b=1 ;b<bin_count;b++){ if (data>=bin_maxes[b-1 ] and data<bin_maxes[b]){ bin_counts[b]++; } } } return 0 ; }
运行结果如下图所示:
实验二:使用Pthread实现任务队列 问题描述 编写一个Pthreads程序实现一个“任务队列”。主线程启动用户指定数量的线程,这些线程进入条件等待状态。主线程生成一些任务(一定计算量),每生成一个新的任务,就用条件变量唤醒一个线程,当这个唤醒线程执行完任务时,回到条件等待状态。当主线程生成完所有任务,设置全局变量表示再没有要生成的任务了,并用一个广播唤醒所有线程。为了清晰起见,建议任务采用链表操作。
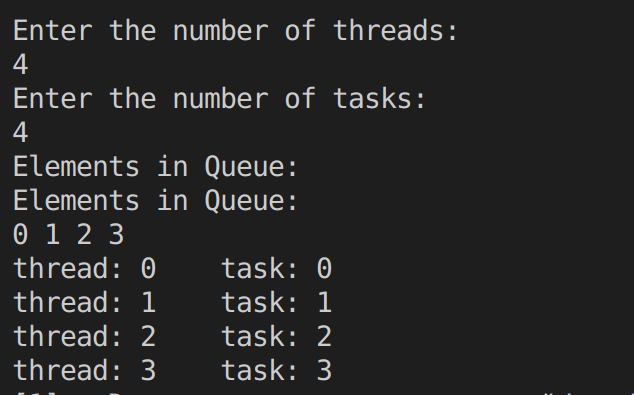
问题解决 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 #include <bits/stdc++.h> #include <pthread.h> using namespace std;typedef struct Node { long task; Node* next; Node (); Node (long t,Node* p=nullptr ){ task=t; next=p; } }Node; class Queue {private : Node* head; Node* tail; int length; public : Queue (){ Node* p=new Node (0 ); head=p; tail=p; } void Display () Node* p=head->next; if (p==nullptr ){ cout<<"Queue is Empty!" <<endl; return ; } cout<<"Elements in Queue:" <<endl; while (p!=nullptr ){ cout<<p->task<<" " ; p=p->next; } cout<<endl; return ; } int size () return length;} void push (long val) Node* p=new Node (val); tail->next=p; tail=p; length+=1 ; } long pop () long ret=head->next->task; Node* p=head->next; head->next=head->next->next; delete p; return ret; } }; pthread_mutex_t mutexx;int thread_count;bool finished=false ;Queue q; void * task (void * rank) int main () cout<<"Enter the number of threads:" <<endl; cin>>thread_count; cout<<"Enter the number of tasks:" <<endl; long n; cin>>n; for (long i=0 ;i<n;i++){ q.push (i); } cout<<"Elements in Queue:" <<endl; q.Display (); pthread_t * threads=(pthread_t *)malloc (thread_count*sizeof (pthread_t )); for (long i=0 ;i<thread_count;i++){ pthread_create (&threads[i],NULL ,task,(void *)i); } finished=true ; for (long i=0 ;i<thread_count;i++){ pthread_join (threads[i],NULL ); } free (threads); return 0 ; } void * task (void * rank) pthread_mutex_lock (&mutexx); cout<<"thread: " <<(long )rank<<" task: " <<q.pop ()<<endl; pthread_mutex_unlock (&mutexx); return NULL ; }
运行结果如下:
实验三:利用OpenMP计算 $\pi$ 的值 问题描述 要求:用两种并行化方法实现,比进行比较分析
问题解决 查阅 $\pi$ 的计算公式如下:
那思路就很简单了,将函数图像向$x$轴作无数条垂线,每两条垂线与图像形成一个梯形。在多个线程中计算梯形的面积,最后累加即可。
函数:$f(x)= \frac{4}{1+x^2}$ ,可用下方代码表示:
1 2 3 4 5 6 double f (double x) double result; result = 4 / (1 + x * x); return result; }
为了公平比较各种方法的运行效率,我假定将图形分为10000000个梯形。
使用critical语句实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <omp.h> #include <bits/stdc++.h> using namespace std;double f (double m) double result; result = 4 / (1 + m * m); return result; } void Trap (double a, double b, int n, double * global_result_p) double h, x, t_result; double lflag, rflag; int i, my_n; int my_rank = omp_get_thread_num (); int thread_count = omp_get_num_threads (); h = (b - a) / n; my_n = n / thread_count; lflag = a + my_rank * my_n * h; rflag = lflag + my_n * h; t_result = (f (lflag) + f (rflag))/2.0 ; for ( i = 1 ; i < my_n-1 ; i++) { x = lflag + i * h; t_result += f (x); } t_result = t_result * h; # pragma omp critical * global_result_p += t_result; } int main (int argc,char * argv[]) double ret = 0.0 ; double a = 0 , b = 1 ; int n = 100000 ; int thread_counts; double start_time; double end_time; thread_counts = 4 ; start_time = clock (); #pragma omp parallel num_threads(thread_counts) Trap (a, b, n, &ret); end_time = clock (); double runtime = (double )(end_time - start_time) / CLOCKS_PER_SEC; cout << "PI evaluation took: " << ret << endl; cout << "Run time took: " << runtime << "s" << endl; return 0 ; }
运行结果如下图所示:
使用private子句和critical语句实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <omp.h> #include <bits/stdc++.h> using namespace std; double f (double m) double result; result = 4 / (1 + m * m); return result; } int main () double my_result, x; double local_a, local_b; int i, local_n; int my_rank; int thread_count; double h; double ret = 0.0 ; double a = 0 , b = 1 ; int n = 10000000 ; int thread_counts; double start_time; double end_time; thread_counts = 4 ; start_time = clock (); # pragma omp parallel private(x,my_result,local_a,local_b,i, local_n,my_rank,thread_count,h) { my_rank = omp_get_thread_num (); thread_count = omp_get_num_threads (); h = (b - a) / n; local_n = n / thread_count; local_a = a + my_rank * local_n * h; local_b = local_a + local_n * h; my_result = (f (local_a) + f (local_b)) / 2.0 ; for (i = 1 ; i < local_n - 1 ; i++) { x = local_a + i * h; my_result += f (x); } my_result = my_result * h; # pragma omp critical ret += my_result; } end_time = clock (); double runtime = (double )(end_time - start_time) / CLOCKS_PER_SEC; cout << "PI evaluation took: " << ret << endl; cout << "Run time took: " << runtime << "s" << endl; return 0 ; }
运行结果如下图所示:
实验四:编写OpenMP程序实现生产者消费者模型 问题描述 编写OpenMP程序,一些线程是生产者,一些线程是消费者。在文件集合中,每个生产者针对一个文件,从文件中读取文本,将读出的文本行插入到一个共享的队列中。消费者从队列中取出文本行,并对文本行进行分词(strtok函数)。符号是被空白符分开的单词,当消费者发现一个单词后,将单词输出。(体会线程安全性)
问题解决 生产者:线程随机产生整数“消息”和消息的目标线程,发送消息给目标线程
消费者:线程从自己的消息队列中取出消息并打印该消息
仍然才用类似于实验二的队列 数据结构,文件Queue.h的编写如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <stdlib.h> #include <iostream> using namespace std;typedef struct Node { long task; Node* next; Node (); Node (long t,Node* p=nullptr ){ task=t; next=p; } }Node; class Queue {private : Node* head; Node* tail; int length; public : Queue (){ Node* p=new Node (0 ); head=p; tail=p; length=0 ; } void Display () Node* p=head->next; if (p==nullptr ){ cout<<"Queue is Empty!" <<endl; return ; } cout<<"Elements in Queue:" <<endl; while (p!=nullptr ){ cout<<p->task<<" " ; p=p->next; } cout<<endl; return ; } int size () return length;} void push (long val) Node* p=new Node (val); tail->next=p; tail=p; length+=1 ; } long pop () long ret=head->next->task; Node* p=head->next; head->next=head->next->next; length-=1 ; delete p; return ret; } };
进行生产者-消费者的并行编写:
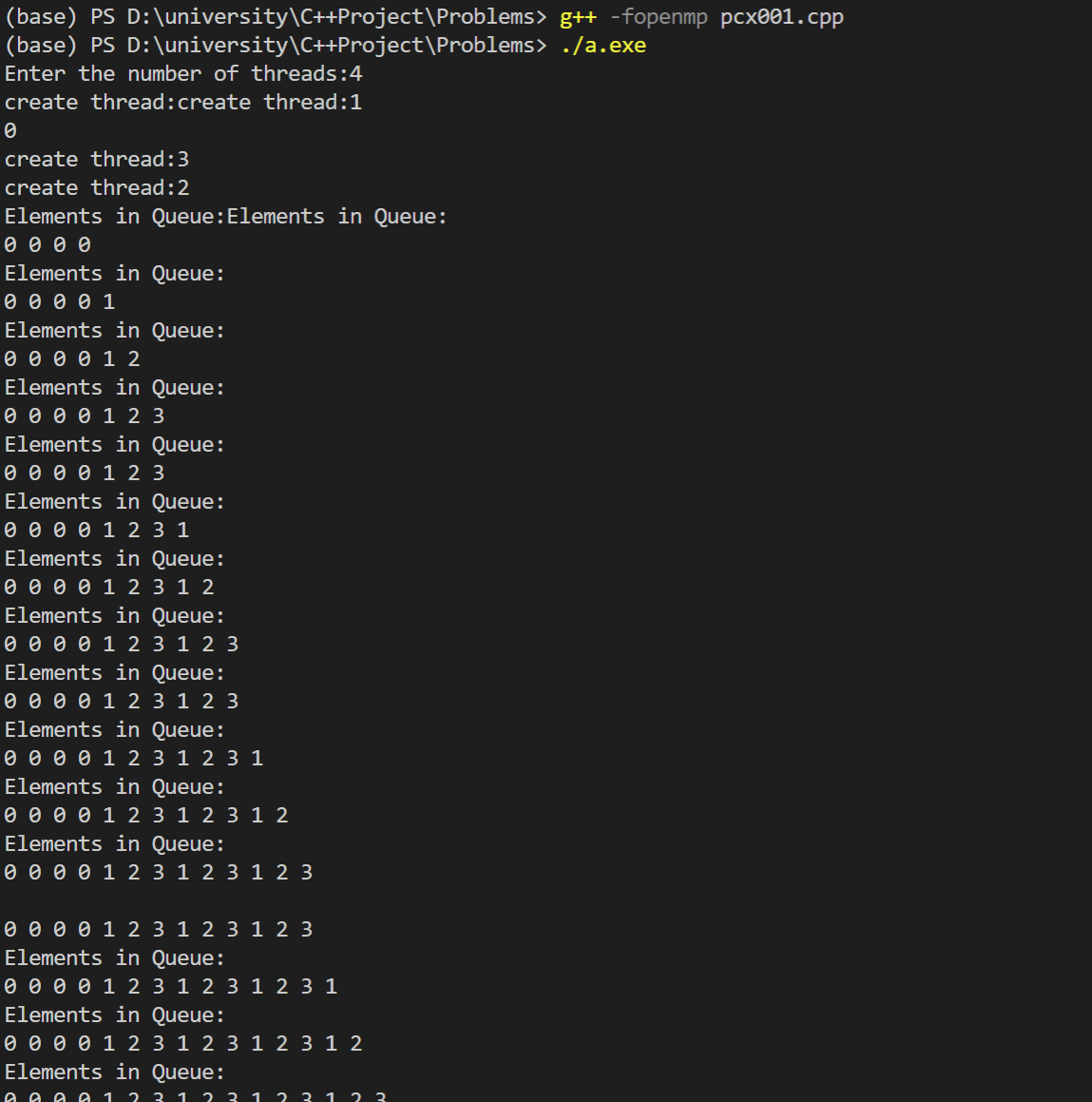
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <omp.h> #include "Queue.h" Queue q; void Send (int i) q.push (i); } void Receive () q.Display (); } int main () int thread_count; cout<<"Enter the number of threads:" ; cin>>thread_count; #pragma omp parallel num_threads(thread_count) { #pragma omp for for (int i=0 ;i<thread_count;i++){ cout<<"create thread:" <<omp_get_thread_num (); printf ("\n" ); } #pragma omp barrier int msgs; #pragma imp for private(msgs) for (int i=0 ;i<thread_count;i++){ for (msgs=0 ;msgs<thread_count;msgs++) { Send (i); Receive (); break ; } } } }
运行结果如下图所示: